Serverless Data Pipeline Guide
Serverless Data Pipelines are increasingly preferred for their ability to handle variable workloads efficiently, minimize operational overhead, and reduce costs through a pay-per-use model. They enable rapid development and deployment, making them ideal for dynamic and innovative environments.
Managed Data Pipelines are suitable for scenarios where workloads are predictable and steady, and where dedicated infrastructure resources can be fully utilized. They require more intensive management and can result in higher costs due to over-provisioning and maintenance needs.
The shift towards serverless architectures reflects a broader trend in the industry towards automation, cost-efficiency, and agility, allowing businesses to focus more on innovation and less on managing infrastructure.
Note: Related Works
Introduction to Serverless Data Pipelines
In today’s data-driven world, businesses need efficient ways to manage, process, and analyze vast amounts of data. Traditional data pipelines, with their reliance on fixed infrastructure, can be costly and inflexible. Enter serverless data pipelines—an innovative solution that offers scalability, cost-effectiveness, and agility. In this article, we’ll explore what serverless data pipelines are, their benefits, key components, and how to get started with building one on AWS.
What is a Serverless Data Pipeline?
A serverless data pipeline is a series of automated processes that move data from one system to another without the need for managing the underlying infrastructure. Unlike traditional pipelines, serverless pipelines leverage cloud-based services that automatically scale, handle resource management, and charge based on usage.
Benefits of Serverless Data Pipelines
- Scalability: Automatically scales to handle varying data volumes without manual intervention.
- Cost-Effectiveness: Pay only for what you use, avoiding the costs of over-provisioned infrastructure.
- Reduced Operational Overhead: No need to manage servers or underlying infrastructure, allowing you to focus on business logic.
- Agility: Rapidly build, deploy, and iterate on data pipelines with minimal setup time.
- Reliability: Leveraging cloud providers’ robust services ensures high availability and fault tolerance.
Key Components of a Serverless Data Pipeline
- Data Ingestion: Collecting raw data from various sources.
- Data Storage: Storing raw data in a durable, scalable storage solution.
- Data Processing: Transforming, cleaning, and enriching the data.
- Data Analysis and Visualization: Querying processed data and creating visualizations.
- Monitoring and Logging: Tracking the performance and health of the data pipeline.
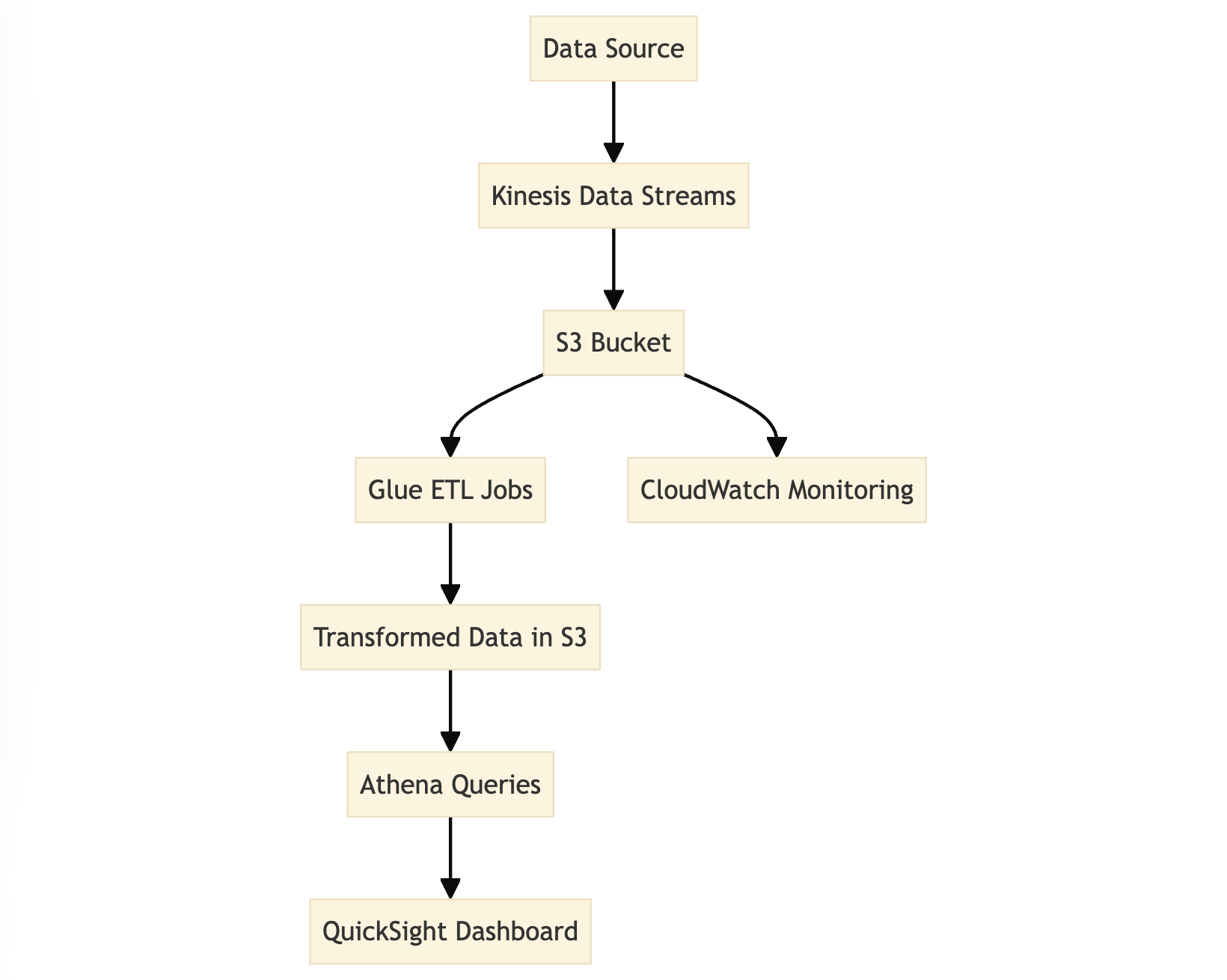
Building a Serverless Data Pipeline on AWS
AWS offers a suite of services that make it easy to build and manage serverless data pipelines. Let’s evaluate the key AWS services used in a serverless data pipeline, comparing them with open-source alternatives in terms of technique, cost, behavior, and benefits.
1. Data Ingestion with Amazon Kinesis
Amazon Kinesis Data Streams is a scalable and durable real-time data streaming service. It allows you to collect and process large streams of data records in real-time.
- Technique: Kinesis uses a partition-based streaming model, similar to Apache Kafka.
- Cost: Pay-per-use model, with charges based on data ingestion and retention.
- Behavior: Automatically scales to handle varying data volumes.
- Benefits: Fully managed, low latency, and integrates seamlessly with other AWS services.
- Comparison: Apache Kafka is a popular open-source alternative. While Kafka offers more control and potentially lower costs for large-scale deployments, Kinesis provides a serverless experience with less operational overhead.
import boto3
kinesis = boto3.client('kinesis')
response = kinesis.put_record(
StreamName='your-kinesis-stream',
Data=b'{"key": "value"}',
PartitionKey='partition-key'
)
2. Data Storage with Amazon S3
Amazon S3 provides scalable object storage for storing raw data. It’s durable, cost-effective, and integrates seamlessly with other AWS services.
- Technique: Object storage with a flat namespace and RESTful API.
- Cost: Pay only for storage used and data transferred.
- Behavior: Infinite scalability with 11 9’s of durability.
- Benefits: Highly available, secure, and supports various storage classes for cost optimization.
- Comparison: MinIO is an open-source object storage solution. While MinIO offers similar features and can be self-hosted, S3 provides a fully managed service with global availability and built-in integrations with other AWS services.
import boto3
s3 = boto3.client('s3')
s3.put_object(
Bucket='your-s3-bucket',
Key='data/file1.json',
Body='{"key": "value"}'
)
3. Data Processing with AWS Glue
AWS Glue is a fully managed ETL (Extract, Transform, Load) service that makes it easy to prepare and transform your data for analytics.
- Technique: Serverless Spark jobs with a managed Hive metastore.
- Cost: Pay only for the compute resources used during job execution.
- Behavior: Automatically provisions resources and scales based on workload.
- Benefits: Fully managed, integrates with AWS services, and supports both batch and streaming ETL.
- Comparison: Apache Airflow is a popular open-source workflow management platform. While Airflow offers more flexibility in workflow design, Glue provides a serverless experience with built-in data catalog and job scheduling capabilities.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
datasource = glueContext.create_dynamic_frame.from_catalog(database="my_database", table_name="my_table")
transformed = ApplyMapping.apply(frame=datasource, mappings=[("col1", "string", "col1", "string"), ("col2", "int", "col2", "int")])
glueContext.write_dynamic_frame.from_options(frame=transformed, connection_type="s3", connection_options={"path": "s3://my-bucket/transformed/"}, format="json")
job.commit()
4. Data Analysis with Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data directly in S3 using standard SQL.
- Technique: Serverless query engine based on Presto.
- Cost: Pay only for the amount of data scanned by each query.
- Behavior: Scales automatically to handle concurrent queries and large datasets.
- Benefits: No infrastructure to manage, fast query performance, and integrates directly with S3.
- Comparison: Apache Hive is an open-source data warehouse software. While Hive offers more control over the underlying infrastructure, Athena provides a serverless experience with no cluster management required.
SELECT * FROM "my_database"."my_table" LIMIT 10;
5. Visualization with Amazon QuickSight
Amazon QuickSight is a scalable, serverless, embeddable, machine learning-powered business intelligence (BI) service built for the cloud. It helps you to create and publish interactive dashboards.
- Technique: Cloud-native BI tool with in-memory computation.
- Cost: Pay-per-session pricing model.
- Behavior: Automatically scales to support thousands of users.
- Benefits: ML-powered insights, embedded analytics capabilities, and integrates with various AWS data sources.
- Comparison: Apache Superset is an open-source BI tool. While Superset offers more customization options, QuickSight provides a serverless experience with built-in ML capabilities and seamless integration with AWS services.
6. Monitoring with Amazon CloudWatch
Amazon CloudWatch monitors your AWS resources and applications, providing you with actionable insights to ensure smooth operation.
- Technique: Centralized monitoring service with custom metrics and alarms.
- Cost: Pay for metrics, alarms, and logs ingested and stored.
- Behavior: Automatically collects and stores logs and metrics from AWS services.
- Benefits: Real-time monitoring, automated actions based on alarms, and integration with other AWS services.
- Comparison: Prometheus is a popular open-source monitoring solution. While Prometheus offers more flexibility in metric collection and storage, CloudWatch provides a managed service with built-in integrations for AWS resources.
import boto3
cloudwatch = boto3.client('cloudwatch')
response = cloudwatch.put_metric_alarm(
AlarmName='HighCPUUtilization',
MetricName='CPUUtilization',
Namespace='AWS/EC2',
Statistic='Average',
Period=300,
EvaluationPeriods=1,
Threshold=80.0,
ComparisonOperator='GreaterThanOrEqualToThreshold',
ActionsEnabled=False,
AlarmActions=[
'arn:aws:sns:us-east-1:123456789012:MyTopic'
],
AlarmDescription='Alarm when server CPU utilization exceeds 80%',
Dimensions=[
{
'Name': 'InstanceId',
'Value': 'i-1234567890abcdef0'
},
]
)
Graph of Data Flow
Conclusion
Serverless data pipelines offer a robust, scalable, and cost-effective way to handle your data processing needs. By leveraging AWS services such as Kinesis, S3, Glue, Athena, and QuickSight, you can build powerful data pipelines that require minimal operational overhead and can scale seamlessly with your business. Whether you’re processing real-time data streams or batch processing large datasets, serverless data pipelines provide the flexibility and efficiency needed to keep up with today’s data demands.
Project Guide
This eBook is designed for practical guide consist of: principles of design, AWS services, codebase with less command line to run entire project.